RS’s egen udtale af ud […] lyder som om det slutter med [θ] (som i engelsk ’thing’ ting)
Grønnum henviser til min udtale på udtaleordbog.dk. Hun bruger det som argument mod min notation [ɤ] frem for Dania-traditionens [ð] som Grønnum selv foretrækker.
Hvorfor [θ]skulle være et godt argument for notationen [ð], er ikke helt klart for mig — hvorfor så ikke [θ]? — men først og fremmest undrede jeg mig over at Grønnum kunne høre denne lyd i min udtale. Jeg har aldrig selv tænkt at jeg udtalte det bløde d med [θ].
Når jeg lytter til min lydfil, er jeg heller ikke enig med Grønnum. Jeg hører ikke [uθ], men en lille smule aspiration efter det bløde d, [uɤ̰ʰ]. Klik på 🔈og døm selv ovre på udtaleordbog.dk.
Nå. Vi kan have hver vores ide om hvad vi hører. Det er ikke ualmindeligt at selv trænede fonetikere er uenige om hvilke lyd man hører, og derfor har vi objektive værktøjer til at afgøre striden.
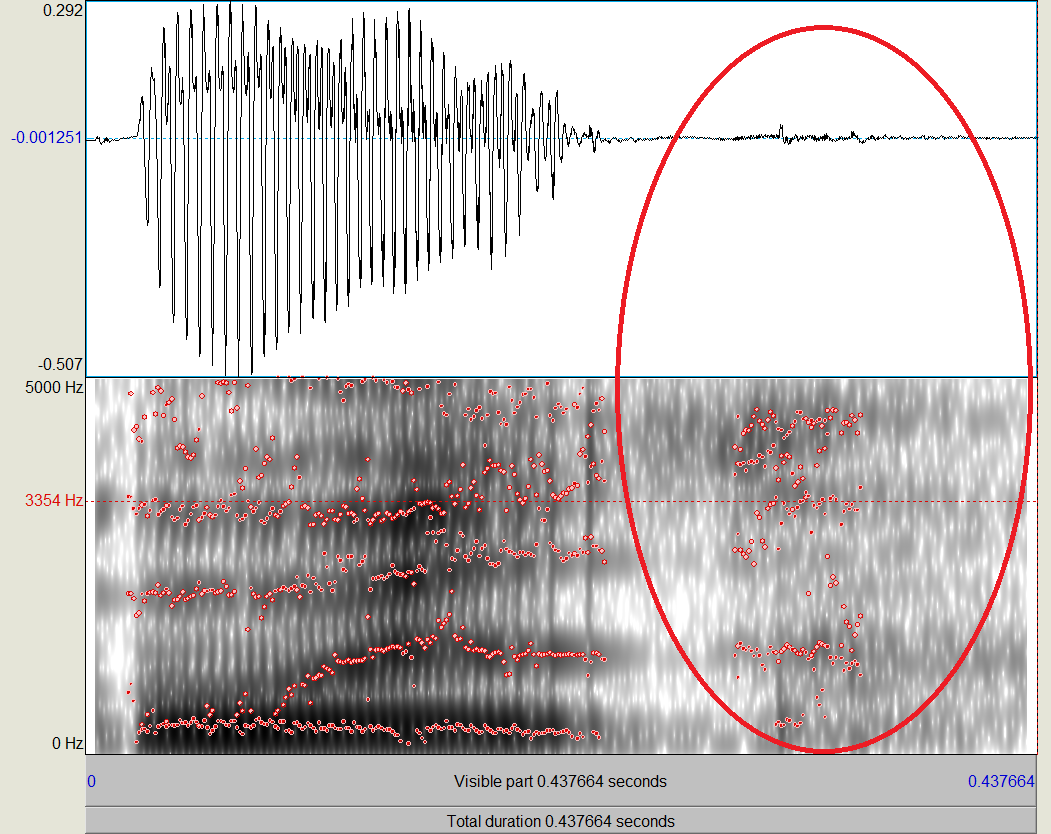
Her er et spektrogram af lydfilen som Grønnum har lyttet til (det er lyden i den røde oval vi er uenige om):
Spektrogram og oscillogram af ‘ud’.
Vis man ikke er inde i akustisk fonetisk analyse, kan det være svært at vide hvad man skal lede efter. I oscillogrammet (øverste halvdel) er der næsten bare en flad streg. Det er det man forventer af et [h]. I spektrogrammet (nederste halvdel) er der en svag antydning af at formanterne (de mørke bånd markeret med røde prikker) fra foranstående vokal [ɤ] sådan set bare fortsætter. Det er også hvad man forventer af [h].
Her er så til sammenligning et spektrogram af [θ], fra lydfilen på wiki:
Spektrogram af [aθaː]
Også en kort forklaring her: Et [θ] er meget kraftigere i oscillogrammet (øverst) og det har sine egne bånd af friktionsstøj i spektrogrammet (nederst) frem for at videreføre formanterne fra de omkringstående vokaler.
Ud fra en ganske simpel akustisk analyse kan man altså se at lyden i slutningen af mit ‘ud’ klart er noget [h]-agtigt og på ingen måde [θ].
Jeg har klippet de to lyde ud så man også kan høre dem isoleret og bedømme om det lyde som samme lyd, aspirationen i ‘ud’ øverst og [θ] nederst.
Min aspiration i ‘ud’Ustemt dental frikativ, [θ]
Såkaldt ytringsfinal aspiration kan forekomme i slutningen af alle lyde der står sidst, før en pause. Når taleorganerne bevæger sig tilbage til hvilestilling, kan der komme en kort udånding, hvilket er det man ser i ‘ud’ ovenfor. Det er ikke en egenskab ved mit bløde d.
Det her er stof som almindelige lingvister lærer på 3. semester på Københavns Universitet. Grønnums ‘jeg kan høre’-argument er lige dovent nok. Hun kunne nemt have brugt to minutter på at sikre at hun ikke brugte et argument som nemt kan afvises.
Jeg blev for nyligt interviewet om hvorfor det er blevet sværere at forstå hvad der bliver sagt i danske film og tv-serier. Interviewet kan læses her, men hvis man gerne vil have pointerne uden at betale abonnement, kan man læse om dem herunder.
(Og så en betydelig tak for inspiration til retoriker Marie Vinther Clausen og skuespiller Camilla Bendix, som jeg deltog i Klog på Sprog med i sommer om samme emne)
Mange beklager sig over at det er svært at forstå hvad der bliver sagt i moderne danske film og tv-serier. Det har været et tilbagevendende tema i mange år, og det er ofte noget jeg diskuterer med folk, når de opdager at jeg er sådan en der interesserer sig for udtalesjusk fonetisk reduktion.
Meget af kritikken går på at skuespillerne (især Mads Mikkelsen) mumler, og kritikken kommer især fra ældre mennesker. Det er derfor nærliggende at afvise det som den sædvanlige sprogsurhed der opstår med alderen hos nogle mennesker.
Men der er nok mere i det end det. Jeg har identificeret fire grunde til at det er blevet sværere at forstå hvad der bliver sagt i fjernsynet. Hver især er grundene nok ikke det store problem, men samspillet mellem de forskellige faktorer gør at det er blevet sværere at være dansk tv-seer end for et par generationer siden.
1. Hørenedsættelse
Det er især ældre der klager over lyden. Jo ældre man bliver, desto dårligere hører man. Det er desværre et uundgåeligt vilkår. Hørenedsættelse er en oplagt faktor.
Men hørenedsættelse forklarer ikke alt. Mange oplever at det specifikt er sproget i dansk drama der er svært at forstå, mens det går fint at forstå andre tv-programmer, radio, lydbøger osv.
Løsning: Der er ikke noget der kan kompensere 100 % for hørenedsættelse. Skru op for lyden, og invester i bedre tv- såvel som høreapparater. Det kan hjælpe noget a vejen.
2. Sprogforandringer
En anden oplagt, aldersbetinger faktor er sprogforandringer. Sproget forandrer sig, og det forandrer sig hurtigere i den yngre generation. Ældres sprog forandrer sig også en smule, men typisk slet ikke i samme tempo som i de yngre årgange.
Sprog forandrer sig i høj grad efter mekanismer som for ældre mennesker opleves som sjusk. Det er ikke bare nutidens unge der “sjusker”; det gjorde de ældre også da de var unge, set i forhold til den daværende ældre generation.
Mekanismen er i grove træk at vi alle veksler mellem mere og mindre formel udtale, men vi taler fortrinsvis uformelt til vores børn, så det er primært den uformelle udtale der videregives til næste generation, og den nye generation finder så sin måde at gøre udtalen mindre formel, mere reduceret.
I mine forældre eller bedsteforældres generation kunne man fx i meget formelle sammenhænge sige /lḭːvəɤ/ livet, men i almindelig, dagligdags udtale blot /liʊ̰ɤ/. Den uformelle udtale, /liʊ̰ɤ/, er blevet min naturlige måde at udtale på, for det er det jeg har hørt og sagt mest. Men i min generation har vi bygget videre på udviklingen. Når jeg taler hurtigt og uformelt, siger jeg blot /liɤ̰ɤ/, som så er blevet udgangspunktet for mine egne børn.
Bl.a. derfor oplever mange ældre de unges udtale som sjusket og mumlet. De unge bruger udtaleformer, som deres bedsteforældre kun vil benytte når de taler meget sjusket, men for unge er det helt normal udtale, og de unge har ikke selv svært ved at forstå det.
Når de ældre skuespillere af helt naturlige årsager udskiftes med yngre, følger sproget med. Det sprog der lød naturligt i den ældre generation, udskiftes med hvad der lyder naturligt for unge, men som er uventet og måske lidt grimt i ældre generationers ører.
Løsning: Man kan ikke forhindre sproget i at forandre sig, men man kan gøre noget for at følge med i forandringerne. Yngre generationers naturlige sprog er objektivt set fuldt ud lige så funktionsdygtigt og forståeligt som ældre generationers.
Det største problem er nok modvilje. Vi har generelt vanskeligere ved at forstå og håndtere ting vi ikke bryder os om. Hvis man først har set sig sur på bestemte skuespillere eller unge mennesker og deres vandaliseren af sproget, så har man sværere ved at forstå dem.
Sprog kræver samarbejde og velvilje. Hvis man insisterer på at synes at de unges sprog er sjusket og dårligt, og at sprogforandringerne var meget bedre i gamle dage, så er det en hindring i at forstå hvad der bliver sagt i fjernsynet. Men vi har alle sammen evnen til at tilpasse sig, akkommodere, til folk der taler lidt anderledes end vi selv. Hvis man er åben over for og sætter sig lidt ind i hvordan og hvorfor sprog forandres, bliver det også lettere at forstå.
3. Ny dramaturgi
Måden man fortæller historier på i dag, er anderledes end for 50 år siden. Når det var meget lettere at forstå Matador end Arvingerne, er det ikke kun hørenedsættelse og sprogforandringer der er på spil. Skuespil, instruktion og manuskript er også noget andet i dag end dengang.
I de seneste årtier, måske mest tydeligt i 90’ernes dogmefilm, har der været en bevægelse væk fra de meget tydelige, velskrevne, indstuderede, men også kunstige, matadorreplikker over mod at lyde naturligt.
De meget planlagte replikker i ældre drama er velegnede til at fortælle historier og skabe mindeværdige citater, men de er ikke gode til at skabe troværdige personer og situationer. Når Mads Mikkelsen skal spille en desillusioneret gymnasielærer i Druk, nytter det ikke noget at han artikulerer som lektor Blomme.
I moderne drama laver man scener hvor man mumler, taler fordrukkent, taler i munden på hinanden, for det gør mennesker i virkeligheden. I virkelige samtaler improviserer vi, kludrer rundt i hvad vi vil sige, og vi forstår ikke altid alle ord. Det er nok ofte slet ikke meningen at man skal forstå hvert enkelt ord i et skænderi eller en middagsbordssituation, men blot fange stemningen.
Den nye måde at skabe drama på forstærker effekten af sprogforandringerne. Skuespillerne artikulerede tydeligere og mere formelt i Matador, selv set i forhold til datidens standard. Springet fra en meget formel, overartikuleret udtale til en mere uformel udtale virker dobbelt, når man samtidig springer fra ældre formel udtale til yngre uformel udtale.
Løsning: Jeg har ikke noget indblik i hvor meget instruktører overvejer cost-benefit i afvejningen af naturlig vs. tydelighed. Jo vigtigere ordlyden i en replik er, des tydeligere bør den fremføres. Forudsat at instruktøren er opmærksom på dette (hvilket jeg ikke er overbevist om at de altid er), så er det altså et spørgsmål om at justere forventningerne til hvordan der fortælles historier. Man kan sagtens se en film eller serie uden nødvendigvis at opfange hvert enkelt ord. Det er måske slet ikke meningen at man skal forstå alt, ligesom vi heller ikke opfanger alt i naturlige samtaler. Men man forstår essensen og følelserne der knytter sig til de enkelte scener, og det er måske det der er meningen.
4. Lydmixning
Det sidste problem jeg vil pege på, er lydmixningen i moderne drama. I ældre film og serier som Matador, er der ingen baggrundslyde eller -musik når der fremføres replikker. Man hører alt og forstår alt.
En del af det at skabe mere naturlige situationer, er at der altid er baggrundslyd når vi taler med hinanden. Der er trafikstøj, naturlyde, andre folk i lokalet, musik eller fjernsyn der kører i baggrunden, glas og bestik der klirrer, osv. Al den baggrundsstøj forstyrrer og gør det sværere at høre hvad der bliver sagt. Men det gør også situationen mere naturlig og realistisk. Det er kun meget få situationer i det virkelige liv hvor der ikke er baggrundslyde når vi taler.
Almindeligvis er vi ret gode til at filtrere baggrundslyde fra når vi taler med hinanden. Vi bemærker dem ikke, men hvis man fjerner dem helt, bliver det alligevel lidt påfaldende. Det er dog velkendt at baggrundslyde gør det ekstra svært for folk med hørenedsættelse at følge med. Derfor virker dette element ekstra forstyrrende på ældre generationer.
Opsamling
Disse fire elementer skubber alle i en retning der gør det sværere at forstå hvad der bliver sagt i moderne danske film og tv-serier. Hver især er de ikke det store problem, men samlet set skaber de problemer.
Man kan nok håndtere en smule nedsat hørelse, eller at studieværterne bliver erstattet med yngre og sproget dermed forandrer sig, eller at ældre skuespillere taler lidt mere naturligt, eller at der indimellem tilføjes lidt baggrundslyd. Men det skaber udfordringer når alle ting sker på en gang.
Det forklarer hvorfor det specifikt er film og serier folk klager over. Det er ikke bare hørenedsættelse eller beklagelser over unges sprog. Det er kombinationen med ny dramaturgi og lydmixning der volder problemer.
Noget af det er instruktørers, skuespilleres og lydteknikeres ansvar, men lidt kan man også gøre selv. Imødekommenhed og velvilje over for forandringer i sprog og historiefortælling kan hjælpe noget af vejen, og det kan nye, forbedrede tv-apparater nok også.
Men på den lidt triste side, så er det også bare et livsvilkår at man i mindre og mindre grad er målgruppen for de nyeste tv-produktioner jo ældre man bliver, så man skal nok ikke forvente for mange hensyn.
For nylig døde det første menneske på månen, Neil Armstrong. I den forbindelse blev der rusket op i en gammel diskussion om hvad Armstrong egentlig sagde da han landede på månen. Spørgsmålet er om han sagde:
One small step for man, one giant leap for mankind, eller One small step for a man, one giant leap for mankind
Vi kan sende folk til månen, men der er stadig meget vi ikke ved om vores eget sprog
I den oprindelige transskription fra NASA er artiklen ‘a’ udeladt, fordi man ifølge NASA ikke kunne høre ordet, selvom Armstrong selv mente at han havde sagt det. Sidenhen er det akustiske signal gennemanalyseret, og det er diskuteret om ordet faldt ud af transsmissionen eller blev kamufleret af statisk støj, eller om Armstrong ganske enkelt lavede en fejl i et af historiens mest berømte citater (hør selv lydklippet her).
Lyde og symboler
Denne gamle diskussion om Armstrongs citat illustrerer noget der ligner et paradoks, som i virkeligheden er ganske normalt, nemlig at ord ofte udtales som ingenting, selvom vi tydeligt hører dem.
Sagen er at sproget består af en lydside og en symbolside. Lydsiden er det rene fonetiske signal, de lydbølger der dannes af vores taleorganer, transmitteres gennem luften og opfanges af vores ører. Symbolsiden er de abstrakte symboler – ord, betydninger, fonemer – der aktiveres inde i vores hjerner når vi taler og lytter.
Fortalerne for udeladelsen af ‘a’ baserer deres argumenter på en forestilling om at der til hvert abstrakte symbol skal svare en vis mængde akustisk materiale. Ordet er der ikke fordi det ikke modsvares af et bestemt akustisk signal. De sætter mao. lighedstegn mellem det akustiske signal og de abstrakte symboler.
Er der noget hvis man ikke kan høre det?
For at demonstrere urimeligheden i denne diskussion kan man starte med at spørge om der er et ‘h’ i [ves]. Svaret på dette kommer sandelig an på om man tænker på ordet hvis eller vis. Hvis man laver ortografisk transskription af en monolog hvor [ves] forekommer, vælger man naturligvis det grammatisk korrekte ord.
Man kan også betragte ord der kan udtales med flere eller færre lyde. I DanPASS-korpusset er ordet jernbaneoverskæring transskriberet bl.a. på følgende måder (og mange andre):
[ˈjæɐ̯nbæːnəɒwəsgɛɐ̯ˀeŋ]
[ˈjæɐ̯nbæːnɒːɐsgɛɐ̯ˀeŋ]
[ˈjæɐ̯nbænʌsgɛŋˀ]
Ingen vil vel påstå at der er tale tre forskellige ord her – jernbaneoverskæring, jernbanåreskæring og jernbanåskæng. Vi identificerer det som samme ord, uanset hvordan bliver udtalt. En ortografisk transskription er mao. ikke en fonetisk præcis gengivelse.
Pointen er altså at de rigtige symboler i hjernen sagtens kan være eller blive aktiveret selvom de ikke modsvares 1-til-1 i den fonetiske form. De aktiveres af den grammatiske og semantiske kontekst. Vi aktiverer ordet jernbaneoverskæring, og de mange symboler (lydlige, grammatiske, semantiske) som det ord i sig selv indeholder, selvom de ikke manifesteres fysisk.
Og vi gør det hele tiden. I min ph.d.-afhandling har jeg registreret at 68 % af alle ord i DanPASS-korpusset udtales med færre lyde eller andre lyde end vi ville forvente i den mest distinkte udtale. Alligevel (eller måske netop derfor) fungerer kommunikationen i de fleste tilfælde perfekt.
Når hele ord udtale som ingenting
Da det enkelte fonem kan realiseres som ingenting, kan det også ske at alle fonemer i et ord realiseres som ingenting, og ordet udtales dermed som ingenting. I DanPASS har jeg fundet 854 ord der således ikke har noget fonetisk signal. I alle tilfælde er der tale om grammatiske småord, i langt de fleste tilfælde ordet er.
Ord
nulrealiseringer
er
517
jeg
87
at
53
i
38
og
34
et
24
en
14
har
12
jo
11
det
11
Det karakteristiske for sådanne ord er at de dikteres grammatisk og semantisk, selvom de ikke nævnes. Hvis der ikke er et udtalt verbum i en sætning, er defaultverbet er. Og hvis der ikke er noget andet subjekt, er defaultsubjektet jeg osv. Dermed kan vi sagtens ikke-udtale sådanne ord og stadig udtrykke dem på anden vis, nemlig via grammatikken og vores fælles sprogforståelse.
En anden karakteristisk ting er at ordene forsvinder i en lignende fonologisk kontekst. Ordet jeg kan forsvinde efter har, som har samme vokallyd, så har jeg udtales [hɑ], og vice versa, jeg har kan udtales [jɑ]. På den måde kan man sige at de tilbageværende ord får en fonetisk dobbeltrolle med at udtrykke begge ord.
Tilbage til Armstrong
I det berømte citat siger Armstrong i mine ører for a man, udtalt [fə˞ ˈmæːn]. Selvom artiklen ‘a’ ikke har noget selvstændigt fonetisk udtryk, så dikteres det af grammatikken, og [fə] har dobbeltrollen med at udtrykke både for og a.
I en mere distinkt form kunne det måske udtales [fəɹə ˈmæːn], men det er uhyre almindeligt at trække sådanne grammatiske småord sammen til en enkelt fonetisk form. Vi gør det selv hele tiden. Vi siger [ded] det er et, [snɔð] sådan noget, [sgweg] skulle vi ikke, osv. Men at ord og fonemer ikke udtrykkes i en bestemt, isolerbar fonetisk form, er ikke ensbetydende med at de ikke skal tages med i en abstrakt transskription. I modsat fald skulle størstedelen af verdens berømte citater skrives om.